






While there are many factors that can go into PC purchase decisions, performance still ranks as the top concern for companies of all sizes. Many companies look to performance benchmarks to help determine which system would best meet their needs. Yet, these benchmarks may not provide the complete performance picture. Are they based on professional applications or mostly consumer workloads? What were the environmental conditions? In this article, we’ll look at some key considerations for using benchmarks to evaluate the performance of modern business PCs—and how to ensure that you choose the right system for current and future needs.
The Old-School Method Of Measuring PC Performance
Traditionally, companies have used various physical specifications, such as processor frequency and cache size, to set a baseline for PC performance. There are two problems with this approach. First, you can have two processors that operate with the same frequency and see dramatically different performance due to the efficiency of their underlying implementations, something measured as “Instructions Per Clock” (IPC). The second problem is that for most modern processors, frequency is not a constant. This is especially true for processors in notebook PCs, where the frequency is constrained by thermal considerations. Frequency will also vary dramatically depending on the type of task being performed, the task duration, the number of cores being used, etc.
Evaluating Performance With Real-World Tests
Modern applications are highly complex, involving different underlying algorithms and data access patterns. As a result, the measured efficiency of a processor—that is, its IPC—will often vary substantially between applications and even between workloads. Many applications include functions that involve displaying graphics on the screen, reading data from storage or even the network; for these workloads, CPU performance, while important, is not the only factor to consider.
One of the best ways to evaluate the performance of a new PC is to conduct a real-world test. In other words, have actual users perform their everyday tasks in the working environment using real-world data. The experience of these users will likely correlate better with their future satisfaction, and it will be more accurate than any published benchmark. This approach is not without downsides, however, including the time required to perform the evaluation, the difficulty of deciding which workloads to measure, and the challenge of measuring performance in a consistent, reliable, and unbiased manner.
Beyond individual user testing, the next-best approach would be for in-house developers to take input from users and create “bespoke” scripts to measure application performance in a way that matches the priorities of those users. This approach can improve the consistency of performance measurements and provide repeatable results. However, it is still a considerable task and can be difficult to maintain between different PC generations.
Instead, most companies rely on the results of industry-standard PC benchmarks to evaluate system performance. Rather than just using one benchmark, companies can get a broader picture of performance by building a composite score across several benchmarks.
Figure 1 compares three different approaches to evaluating PC performance—benchmarks, application scripts, and user evaluations—and shows how the results have different levels of business relevance.
Figure 1 – PC Evaluation Strategy
What Makes A Good Benchmark?
Two types of benchmarks are commonly used to evaluate PC performance: “synthetic” and “application-based.” Both types can be useful in the decision process, although individual benchmarks can often have undesirable attributes. This can be mitigated by following a general principle of using multiple benchmarks together to get a broader, more reliable picture of performance.
A good benchmark should be as transparent as possible, with a clear description of what the benchmark is testing and its testing methods. In the case of application-based benchmarks, this allows buyers to understand whether the workloads being used match their organization’s usage. Without sufficient transparency, the question can also arise as to whether the tests are selected to highlight one particular architecture over another.
Not All Application-Based Benchmarks Are Equal
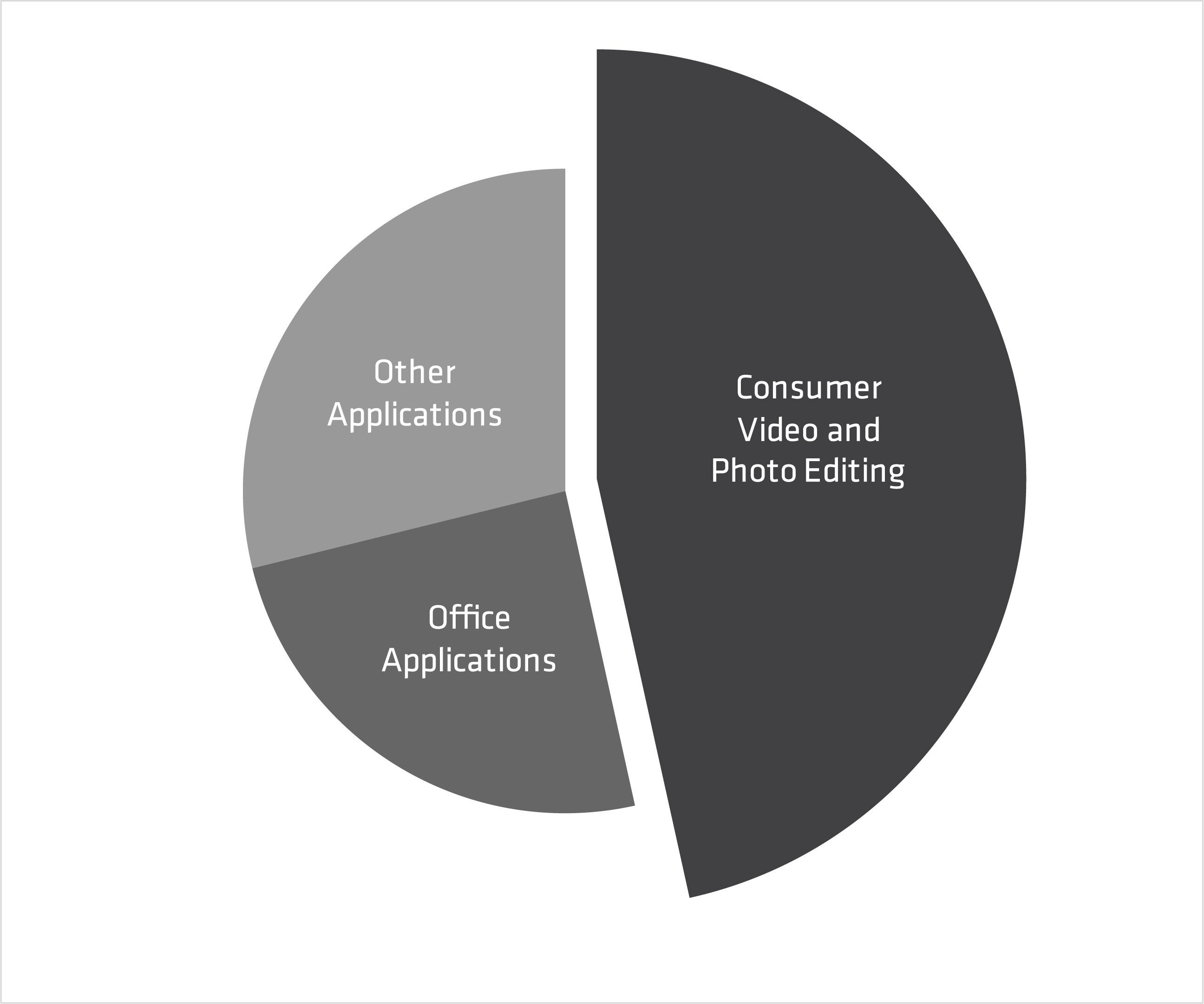
The tests in application-based benchmarks should represent the workloads that are most relevant to the organization. For example, if 30-50% of a benchmark comes from applications that are seldom used in a commercial setting, then that score is probably not relevant. Consider the benchmark in Figure 2, which is based primarily on consumer-type workloads and has a low percentage of office application use. Therefore, this benchmark would likely not be useful for most commercial organizations.
 AMD
AMD
Figure 2 – A benchmark composition not suitable for commercial environments
Some application-based benchmarks measure the performance of off-the-shelf applications, but they may not represent the version of the application deployed in the organization or include the latest performance optimizations from the software vendors. This is where synthetic benchmarks come in.
Evaluating The Performance Potential Of A Platform
Unlike application-based benchmarks, synthetic benchmarks measure the overall performance potential of a specific platform. While application benchmarks show how well a platform is optimized for certain versions of certain applications, they are not always a good predictor of new application performance. For example, many video conferencing solutions use multiple CPU cores to perform functions, such as the usage of virtual backgrounds. Synthetic benchmarks that measure the multi-threaded capability of a platform can be used to predict how well a platform can deliver this new functionality.
With synthetic benchmarks, it is important to avoid using a narrow measure of performance. Individual processors, even in the same family, can vary in how they handle even a small piece of code. A synthetic benchmark score should comprise several individual tests, executing more lines of code that exercise different workloads. This provides a much broader view of the platform performance.
Multi-Tasking Is Hard To Benchmark
Application benchmarks have a hard time simulating the desktop workload of a modern multi-tasking office worker. The reason for this is that running multiple applications simultaneously can add a larger margin of test error than simply testing one application at a time. Synthetic applications that measure the raw multi-threaded processing power of a platform are a good proxy for the demands of today’s multi-tasking users.
A best practice is to consider both application-based and synthetic benchmark scores together. By combining scores using a geometric mean, you can account for the different score scales of different benchmarks. This provides the best picture of performance for a specific platform, considering the applications used today and providing for the future.
Other Important Considerations
Benchmarks are an important part of a system evaluation. However, these powerful tools can have some key limitations:
- Measured benchmark performance can vary by operating system (OS) and application version—ensure that these versions match what’s in use in your environment.
- Other conditions can impact scores, such as background tasks, room temperature, and OS features such as virtualization-based security (VBS) enablement. Again, ensure that the conditions are the same and match your deployments.
- Some users may use relatively niche applications and functions not covered by the benchmarks. Consider augmenting benchmark scores with user measurements and correlating them with synthetic benchmark scores.
Beware Of Measurement Error
Any measurement will have a margin of “measurement error,” that is, how much it may vary from one test to another. Most benchmarks have an overall measurement error in the 3-5% range, caused by a variety of factors including the limitations of measuring time, the “butterfly effect” of minor changes in OS background tasks, etc. One way to overcome this error would be to measure results five times, discard the highest and lowest scores, and take the mean of the remaining three scores.
It is important to consider measurement error when setting requirements in purchase requisitions. If a score of X correlates well with user satisfaction, then the requisition should stipulate that scores should be within [X-Epsilon, Epsilon] where epsilon is the known measurement error. When epsilon is not known, it is reasonable to assume it is in the 3-5% range of the target score.
Conclusion
Correctly evaluating performance is not a one-dimensional task. There are several techniques that can be used by an organization to determine which system would best meet their needs. Using a narrow benchmark score may lead to incorrect conclusions, while the best overall picture of performance comes from looking at a wide range of both application-based and synthetic benchmarks.
The final and best step in any evaluation is to allow groups of users to “test-drive” systems in their actual work environment. No matter how well a system scores on benchmarks or on application scripts, users must be satisfied with their experience. Whether you use benchmarks, application scripts, or organizational trials to measure performance, the AMD Ryzen PRO 4000 series of processors delivers new levels of speed and efficiency to delight today’s users. Learn how to get the notebook PC performance to address today’s computing requirements, along with the power to meet future business demands.
For more information on how AMD Ryzen PRO processors can meet the performance needs of your organization, visit: https://www.amd.com/en/processors/laptop-processors-for-business or https://www.amd.com/en/ryzen-pro